ICLR 2020: Efficient NLP - Transformers
Highlights from my favorite Transformers-related papers at ICLR 2020
I was lucky enough to volunteer and attend (virtual) ICLR 2020. It delivered a huge amount of learning for me and I was fortunate to join some really great discussions.
Efficient NLP was big focus of many of the papers and here I will focus on a few of the more well known transformer architectures proposed over the past year or so; Reformer, ELECTRA, Lite Transformer and ALBERT. Towards the end of this article I also mention additional ICLR summaries that are worth reading 🙂
Note: ICLR Videos Now Online!
All of the ICLR paper talks and slides are now online, I highly recommend watching the 5 to 15minutes videos accompanying each of the papers below for some excellent summaries and additional understanding
#ICLR2020 Public Archive - https://t.co/EpXWIK0ujS
— Sasha Rush (@srush_nlp) May 4, 2020
* ~700 short talks with synced slides, papers, and code
* 8 keynotes with moderated QA
* 15 workshops on topics ranging from climate change to AfricaNLP. pic.twitter.com/FVX2JJUYVZ
Efficient NLP - Transformers
New transformer architectures that promise less compute-intense NLP training, in order of my excitement to use them:
⚡ Reformer: The Efficient Transformer ⚡
- Reformer enables training on much longer sequences than BERT-like models (e.g. document-length sequences instead of 512 token length sequences) much more efficiently
Reformer introduces a couple of techniques that improve both time and memory efficiency:
Technique 1: Reversible residual connection layers (originally used in computer vision in RevNets) instead of the standard residual layers improves memory efficiency:
![]()
- Technique 2: Locality-Sensitive Hashing (LSH) based attention replaces dot-product attention (and is much faster) which reduces the time complexity:
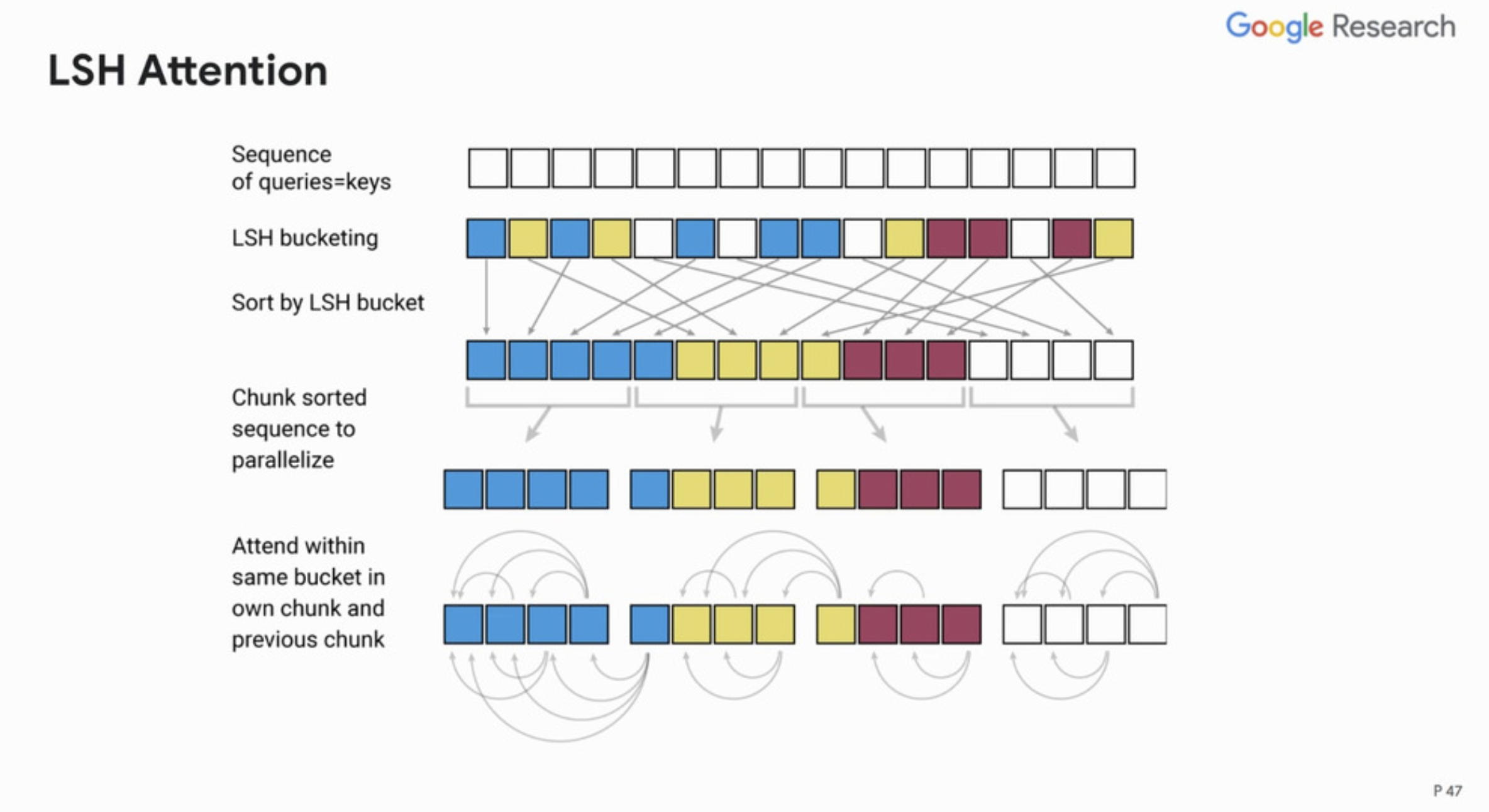
- The 15 minute ICLR paper presentation video linked above really helps better understand these concepts
- A PyTorch Reformer implementation can be found here
⚡ ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators ⚡
- ELECTRA brings a couple of novelties, resulting in a much more computationally efficient transformer to train. It is trained with:
- a Generator-Discriminator setup and
- a new pre-training task called Replaced Token Detection
- The Generator is trained to replace masked tokens (as per the standard MLM task), the Discriminator then tries to identify the token that has been replaced
![]()
- One subtle thing to note is that if the generator happens to generate the correct token then that token is considered "real" instead of "fake"
- ELECTRA-small can be trained on a single V100 GPU (4 days)
- It is slower per epoch than other transformers, but it converges faster resulting in an overall faster training:
the model learns from all input tokens instead of just the small masked-out subset, making it more computationally efficient
- Very strong results and it's performance scales up as the architecture is made larger
- Lots more interesting results and experiment discussion can be found in the paper
- A HuggingFace ELECTRA Implementation is here
⚡ Lite Transformer with Long-Short Range Attention ⚡
Introduces Long-Short Range Attention (LRSA) which results in a reduction in model computation between 2.5x and 3x compared to original Transformer.
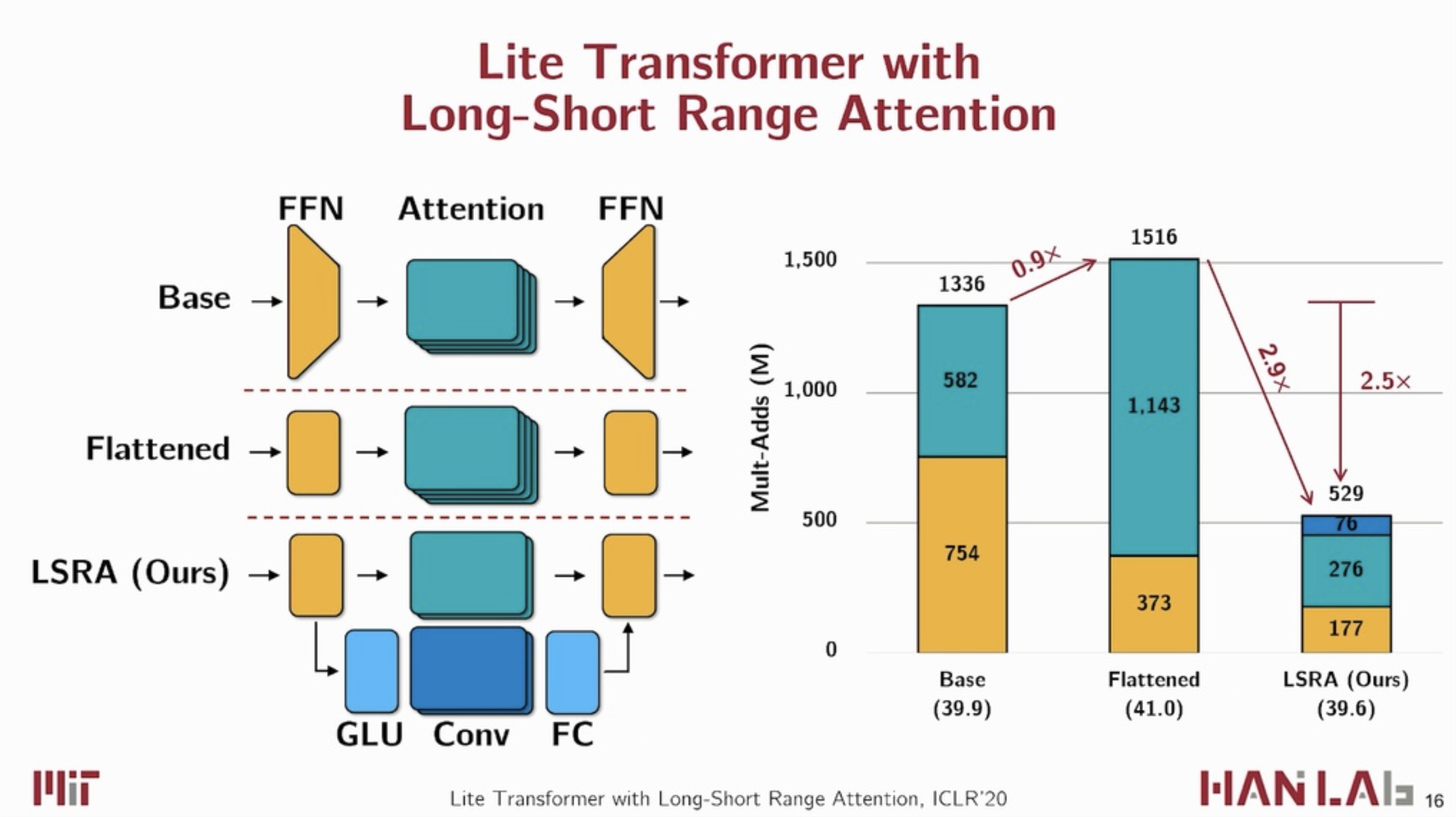
The new architecture enables 2 different perspectives on the input sequence:
...one group of heads specializes in the local context modeling (by convolution) while another group specializes in the long-distance relationship modeling (by attention)...
The LSRA architecture and where the attention is focussed can be seen here:
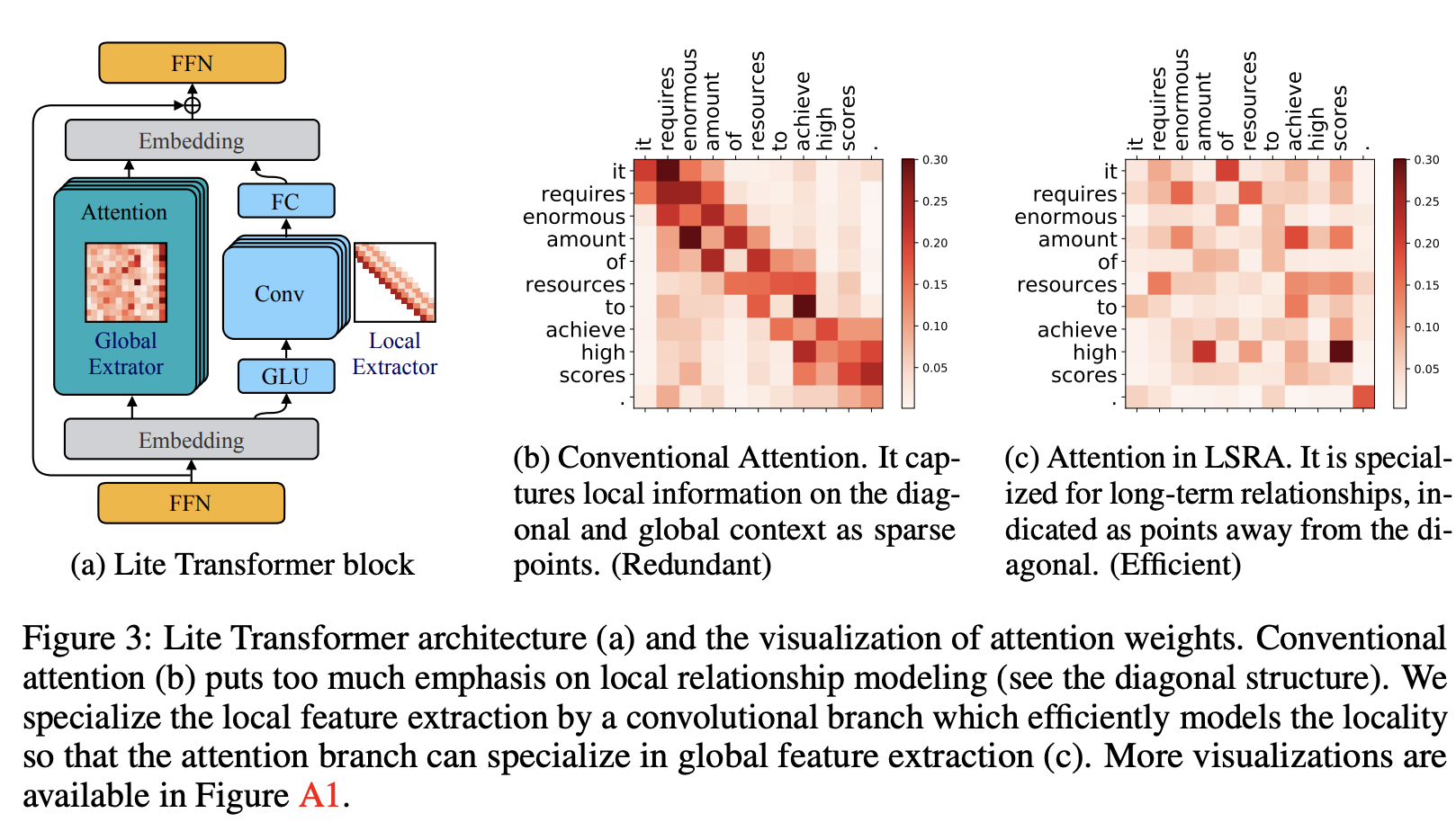
- Lite Transformer performs well against the original Transformer for translation, summarisation and language modelling
- One thing I liked is that Lite Transformer looks at performance under mobile-like constraints, defined by the authros as 10M parameters and 1G FLOPs
- Lite Transformer code (PyTorch) is available from the authors here
⚡ ALBERT: A Lite BERT for Self-supervised Learning of Language Representations ⚡
- ALBERT is 18x smaller model than BERT-large and can be trained 1.7x faster while still outperforming it
- The two techniques used to reduce its size are:
- Reduce the vocabulary embedding size; they reduce the matrix size by projecting it to a lower dimension. e.g. an input one-hot encoded matrix of size 30,000 is reduced to a much smaller sized matix which is then used
- Cross-layer parameter sharing; they use the same operations and repeat them multiple times. This helps the parameter size of the network growing as layers as added
- ALBERT uses 3 training tricks to further improve its performance:
- Uses MLM and Sentence Order Prediction (SOP), a self-supervised loss that focuses on modeling inter-sentence coherence
- Does not use dropout (due to the huge amount of data available)
- Uses 10x more data than BERT-Base
- HuggingFace PyTorch ALBERT code can be found here
![]()
Other Great Summaries to Read
Other great summaries from ICLR attendees are below, the Google Doc in Yacine's tweet below gives brief summaries to even more papers that I haven't covered here
Marija Stanojevic on mentorship tips for aspiring ML Researchers, @mstanojevic118
Analytics Vidhya with a summary of the event and what the most used opensource tools were
To Close
Research work on efficient NLP is moving rapidly and it was fascinating to see so many different approaches on display at ICLR this year, myself and my single GPU are super excited to see how fast things will develop this year 😆
This was also the first ML conference I attended and found the (covid-caused) virtual format to work exceptionally well, my huge congrates to all of the organisers involved in pulling off a massive amount of work in such a short amount of time!
As always, I would love to hear if you have any comments, thoughts or criticisms at @mcgenergy