ICLR 2020: Efficient Deep Learning and More
Highlights from my favorite Deep Learning efficiency-related papers at ICLR 2020
I was lucky enough to volunteer and attend (virtual) ICLR 2020. It delivered a huge amount of learning for me and I was fortunate to join some really great discussions.
Efficient Deep Learning was big focus of many of the papers and in this second ICLR2020 article* I will focus on techniques presented that either enable more efficient training and/or inference from the papers I managed to see. There are also a couple of bonus papers I really liked at the end of this article.
*In my first ICLR2020 article I highlight some of the new, more efficient transformer achitectures presented such as ELECTRA, Reformer and more.
Note: ICLR Videos Now Online!
All of the ICLR paper talks and slides are now online, I highly recommend watching the 5 to 15minutes videos accompanying each of the papers below for some excellent summaries and additional understanding
Efficient Deep Learning
Training methods and architecture changes that can make Deep Learning models smaller/more efficient
⚡ Reducing Transformer Depth on Demand with Structured Dropout ⚡
- The introduction of LayerDrop in this paper was super exciting to read as it makes a (transformer) model much more robust to pruning while only having to train it once, unlike finding lottery tickets for example
- Essentially the idea is simple, just randomly remove/skip different layers during the forward pass in training like so:
![]()
- LayerDrop can be implemented like so (see the link below for the author's full codebase)
layer_drop = 0.2 # The authors dropped the layers with a 20% probability in all of their experiments for layer in transformer.layers: if random(0,1) > layer_drop and self.training: x = layer(x) - This training setup confers 3 benefits:
- Increased Training Speed (training less layers)
- in training the percentage increase in words per second increased almost linearly with the percentage of layers dropped
- Strong regulariser
- NLP models trained with layerDrop seem to perform better than baseline models trained without it (e.g. EN-DE Transformer performance improvement)
- Increased robustness of deeper models which enables you to increase the number of layers in your model. The authors doubled the encoder depth in their WMT14 EN-DE transformer translation model for a new SOTA BLEU score.
- Increases model stability
- Note the authors also reduced DropOut slightly when training to compensate for the additional regularisation of LayerDrop
- Reduction in model size
- A model trained with LayerDrop can be pruned to any desired depth for inference and still maintain robust performance without additional fine-tuning
- The specific type of pruning used for inference also did not seem to matter although dropping every other layer seemd to offer strong performance while being straightforward to implement
- Increased Training Speed (training less layers)
- Unfortunatley when I asked during the Q&A whether this could be applied to when fine-tuning existing pre-trained transformer models, such as those in HuggingFace's library, one of the authors replied that they had tried it but it didn't have great results. Their theory was that these transformers had learned so much during pre-training that a little bit of fine-tuning using LayerDrop wasn't able to have enough of an influence on the model weights to confer this robustness.
- Code for LayerDrop and models pre-trained with LayerDrop can be found here.
- If you want to use RoBERTa but find it too large/slow for inference then you should give the models here a go!
⚡ Playing the lottery with rewards and multiple languages: lottery tickets in RL and NLP ⚡
- This work is a follow on from The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks from Jonathan Frankle, Michael Carbin at FAIR, who's research codebase has just been released by the way:
I just open-sourced my codebase for research on neural network pruning, the Lottery Ticket Hypothesis, and other topics in deep learning. It's written in PyTorch and designed to make it easy to add new models, datasets, and experiments. Check it out: https://t.co/JyTGT8RRZW
— Jonathan Frankle (@jefrankle) May 7, 2020 - At ICLR 2020 they present how the lottery ticket phenomenon, which previously was only explored for vision models, applies more generally to deep neural networks across NLP and reinforcement learning.
- They test it with NLP models, LSTMs and Transformer, as well as reinforcement learning models and found that the lottery ticket sub-networks performed better than randomly pruned networks, as was found in their previous work on vision models.
![]()
- The authors used Iterative Pruning with Late Resetting (aka Late Rewinding):
The trick is that the subnetworks don't always emerge at initialization. Instead, we found that training these subnetworks from an iteration slightly after initialization (between a few iterations and a few epochs) often works much better. We term this technique "late resetting."
— Jonathan Frankle (@jefrankle) March 6, 2019 - Currently the downside to discovering lottery tickets is that they are very computationally expensive to discover. Here the authors trained the models to convergence, before pruning ~20%, reinitializing and training again. Several cycles of this requires significant computational resources for large models such as transformers and reinforcement learning frameworks. However once a lottery ticket is found it can be trained quickly due to its reduced size whilst still maintaining almost the same performance of the original full network.
- I'd also recommend watching the authors second ICLR 2020 paper, "The Early Phase of Neural Network Training", which explored how the "Early Phase" of the network training, i.e. the point at which lottery ticket sub-networks emerge (and the point at which Late Resetting would reset to) was impacted by variations to the input data and weight distributions.
⚡ Dynamic Model Pruning with Feedback ⚡
- The paper introduces a dynamic way to prune weights (Dynamic Model Pruning with Feedback, or DPF) that allows previously pruned model weights to be re-activated when needed, resulting in lottery-ticket peformance of the pruned models while only needing to be trained once (unlike lottery tickets which need multiple rounds of training)
![]()
- They achieve state-of-the-art top-1 accuracy for pruning on CIFAR-10 and Imagenet for unstructured weight pruning
- The gradient is evaluated for the pruned model and then applied to the dense model. The binary mask is periodically updated to reallocate the weights. The intuition is that the gradient is used to measure the "error" and then the dense model is used to correct this error
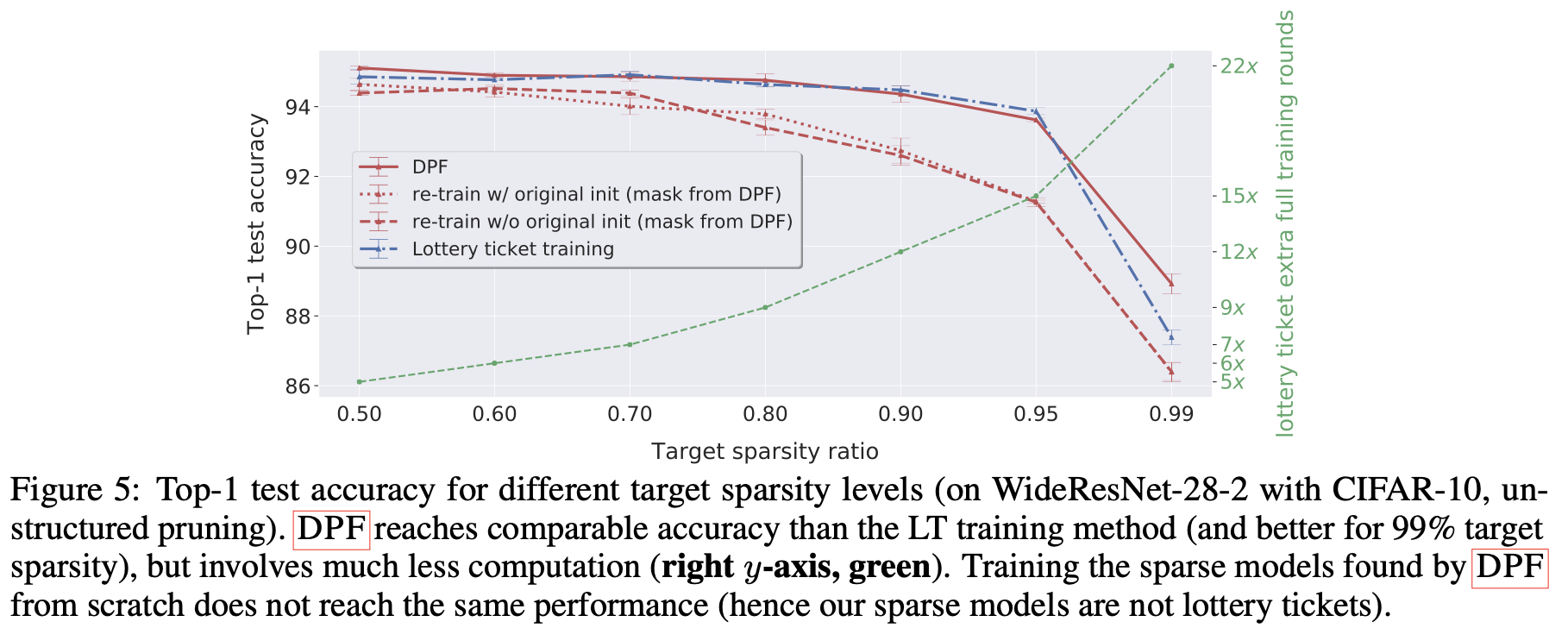
- Unstructured magnitude pruning was used
- The authors say that the code will be released in June
⚡ Once for All: Train One Network and Specialize it for Efficient Deployment ⚡
- The idea here is that a single large model can be trained the contains a multitude of high performant sub-networks. These sub-networks can be pruned for use in a wide variety of edge device types and sizes without additional training. The author's focussed on training efficient vision models for this paper.
![]()
- This enables strong performance on a wide variety of devices, without incurring the computational expence (and CO2 footprint) of searching for specialised architectures for each device
![]()
- The key to training this model is a technique called Progresive Shrinking which is a:
a generalized pruning method that reduces the model size across many more dimensions than pruning (depth, width, kernel size, and resolution)
![]()
- They achieved 1.5x lower latency for MobileNet-V3 and 2.6x for EfficientNet in ImageNet mobile setting while maintaining the same accuracy
- Their Code and 50 pre-trained models (for many devices & many latency constraints) can be found in their gihub
Other Great Papers You Should Absolutely Checkout 💯
There were many other super interesting papers I couldn't cover there, some of my favorites are below
Optimisation
Towards Stabilizing Batch Statistics in Backward Propagation of Batch Normalization
- Introduces Moving Average Batch Normalization (MABN) for training with small batches
- Restores BatchNorm-like performance when training with small batches, down to bs=1 (BatchNorm tends to suffer when training with small batches)
- Code here
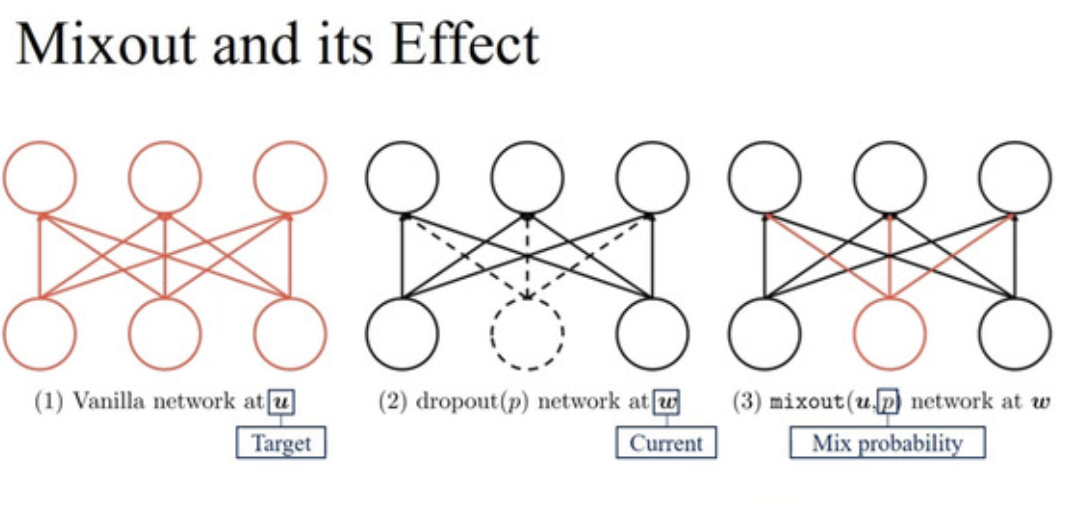
Mixout: Effective Regularization to Finetune Large-scale Pretrained Language Models
- Useful for stabilising training on fine-tuning (BERT for downstream task for example)
- Motivated by DropOut (which is a special case of DropConnect)
- Replaces a randomly selected parameter with a "target" parameter, instead of zero as in DropOut, from a previously memorised state
- Code here
Vision
- Correlations between pixels and between channels can make image recognition more difficult, the authors propose network deconvolution to solve this
- Achieves impressive performance gains across ResNet, ResNeXt, EfficientNet, VGG (and more) in both image classification and semantic segmentation tasks, even when BatchNorm is removed
- Network Deconvolution seems to hold promise beyond vision models too:
Also, the same deconvolution procedure for 1 × 1 convolutions can be used for non-convolutional layers, which makes it useful for the broader machine learning community.
- Code here- Network Deconvolution has also been discussed and implemented in the fastai forums
![]()
How much Position Information Do Convolutional Neural Networks Encode?
- Adding zero-padding (widely used already) implicitly delivers positional information and imrproves vision performance
- Deeper models can better encode positional information
Thanks for Reading 😃
As always, I would love to hear if you have any comments, thoughts or criticisms at @mcgenergy